

[If you enjoy the show, consider supporting us on Patreon! You pay a small fee for each episode we publish.]
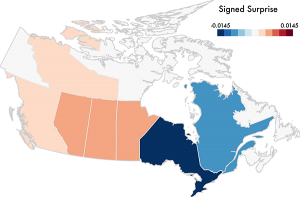
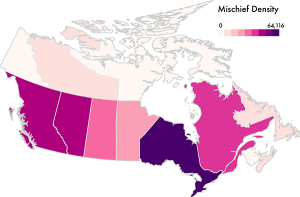
In this episode, we have Michael Correll and Jeff Heer from the University of Washington to talk about a novel visualization technique they developed called “Surprise Maps”: a new kind of map which visualizes what is most surprising in a dataset.
Using their own words: “The idea behind Surprise Maps is that when we look at data, we often have various models of expectation: things we expect to see, or not see, in our data. If we have these models, we can also measure deviation or difference from these models. This deviation is the unexpected, the data that surprise us.”
On the show we talk about how they came up with the idea for Surprise Maps, how they work, and potential applications and extensions for the technique.
Enjoy the show!
Data Stories is brought to you by Qlik. Are you missing out on meaningful relationships hidden in your data? Unlock the whole story with Qlik Sense through personalized visualizations and dynamic dashboards which you can download for free at qlik.de/datastories.
Links
- Medium post on Surprise Maps
- InfoVis 2016 Paper on Surprise Maps (PDF)
- Github Repository:
- https://github.com/uwdata/bayesian-surprise
- Formal Bayesian Theory of Surprise: http://ilab.usc.edu/surprise/
- Example of application of Surprise Maps at CensusMapper